Design¶
ASSYST is designed around two principles:
small, orthogonal classes, and
clean, abstract interfaces between them.
This has advantages on heterogeneous HPC: the individual stages of an MLIP-generation workflow require very different resources (serial preparation, multi-node DFT, GPU-accelerated fitting), and a loosely coupled package lets each stage be dispatched independently — e.g. via executorlib. The same loose coupling is what keeps ASSYST future-proof against new MLIP architectures or new reference-data sources.
ASSYST is organised around four small, independent submodules — one per
stage of the training-set construction pipeline. Each submodule exposes a
top-level function that consumes an iterable of ase.Atoms and
produces another iterable of ase.Atoms, plus a family of small,
frozen dataclasses.dataclass() configuration objects that describe
how the stage should behave.
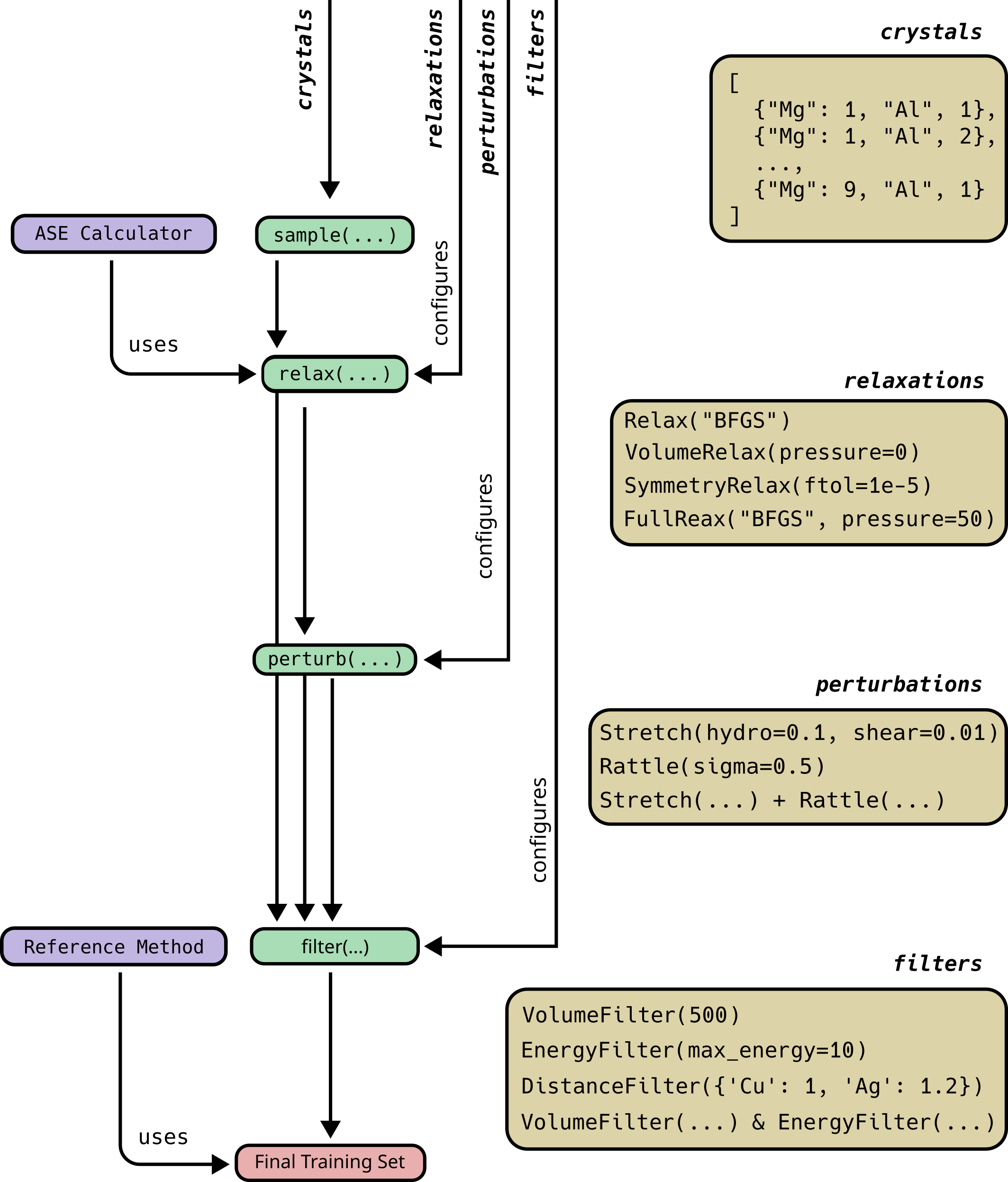
Outline of data and control flow in the package. Green boxes are the
cleanly separated workflow steps; arrows between them show the flow of
generated structures as lists of ase.Atoms. Ochre boxes give
example code for the small modular classes that configure each step.
Violet boxes mark the points where ASSYST loosely couples to external
codes — either via the ASE calculator interface or by overloading a
minimal set of documented methods.¶
The pipeline¶
Reading the figure top-to-bottom, the canonical ASSYST workflow is:
assyst.crystals—sample()enumerates random symmetric crystals for the requested formulas and space groups.assyst.relaxations—relax()minimises each candidate using an ASE calculator, driven by aRelaxsubclass (VolumeRelax,SymmetryRelax,FullRelax, …).assyst.perturbations—perturb()expands each minimum into a cloud of nearby configurations viaRattle,Stretch, and their additive/random combinations.assyst.filters—filter()(the standard built-in) is composed withFilterBasesubclasses such asDistanceFilter,VolumeFilter,EnergyFilter, andForceFilterto discard pathological structures.
The stages are deliberately decoupled: each takes plain ASE atoms in and emits plain ASE atoms out, so any step can be skipped, swapped, or re-ordered without touching the others.
Why configuration objects?¶
Every stage separates what to do (the top-level function) from how to do it (the dataclass argument). This keeps three properties stable across the whole API:
Composability. Filters and perturbations support algebraic operators (
&,|,+,RandomChoice) so complex behaviour is built from small pieces rather than added as new keyword arguments.Reproducibility. Configuration objects are frozen dataclasses and therefore hashable and picklable — settings can be stored alongside the generated structures and reloaded verbatim.
Extensibility. Each configuration class is a small subclass with a single hook (e.g.
apply_filter_and_constraints()for relaxations,__call__()for filters). See Custom Relaxers for a worked example of plugging in a non-ASE engine.
Role of the ASE calculator¶
ASSYST never owns a reference method. An ase.calculators.calculator.Calculator
is passed into relax() and is the only place
energies and forces enter the pipeline. All other stages operate on pure
geometry, which is why a single workflow scales unchanged from a cheap
Morse potential during prototyping to production DFT runs.
Provenance and reproducibility¶
Each generated structure carries a UUID in Atoms.info that is updated
by assyst.utils.update_uuid() whenever a stage produces a new
structure from an existing one. Parent/child relationships between
structures are tracked alongside, so the full history of any data point
in the final training set is recoverable; this property is exercised in
the test suite. See Lineage Tracking and Metadata for the
downstream tooling that builds on it.
Where ASSYST relies on random initialisation or perturbation, the state of the underlying random number generators is exposed so that runs can be reproduced bit-for-bit.